snake-game-reinforcement-learning
Project maintained by lila-smith Hosted on GitHub Pages — Theme by mattgraham
Reinforcement Learning with the Snake Game
(This blog post is meant to be part helpful resource and part explanation of my learning. Going into this project, I had no prior knowledge of reinforcement learning. If you would like resources that I found helpful, please view the citations section. I made the original game with Alex. If you want to play our snake game, follow the directions. You can view my reinforcement learning code here.)
So what even is reinforcement learning? And why is it cool?
Reinforcement learning (RL) involves having “an agent”, similar to a trained model in other ML techniques, choose actions based on its current environment. The actions, in turn, have an impact on the environment. Over time, it will learn which actions to take based on its environment.
RL is neither supervised nor unsupervised learning. There is no dataset necessary, just parameters. This means that RL can be used in situations that are difficult to collect data about or don’t involve classification. Instead, you choose what sort of positive or negative reward should be given when something happens in the environment.
State Space
You get to choose what information you tell the agent, and you need to choose wisely!
In the snake game for an 18 by 18 board and a length one snake, there are 324 choices for the location of the snake square and 323 choices for the location of the apple square. Together, this means there are 104,652 possible configurations of the board. Clearly…this cannot be our space. This would require a lot of memory and not end up being super useful, since it would take tens of thousands of games to let the agent have enough experience with each state.
Instead, let’s look at a scenario:


These two environments share a lot in common. While one has a snake facing up and the other down, they both have no walls surrounding them, and there is an apple two squares to the snake’s right.
The optimal action in both scenarios is clearly to turn right, and they are basically just rotations of one another. It makes sense that we should group these two together: anything that the snake learns about one of these scenarios is relevant to the other scenario.
To reduce the dimensions of the state space, let’s think about what factors are important:
- Will it bump into the wall and die?
- Will it approach the apple?
- Will it hit its tail and die?
To allow it information to perform as intended, we need to give it a state space that can help answer these questions.
- If there is an obstacle to left, straight, or right, relative to the snake’s direction.
- Each spot will have a boolean value with
Trueif there is an obstacle there andFalseif there is a Blank space or Apple. There are 8 total combinations of these values: 2 * 2 * 2.
- Each spot will have a boolean value with
- The direction of the apple, relative to the snake’s direction.
- This will be a pair like
[1,1]for right and up or[-1,0]for left. There are 9 possible directions.
- This will be a pair like
- The direction of the snake’s end of tail, relative to the snake’s direction.
- Again, this will be a pair like
[1,1]for right and up or[-1,0]for left. There are 9 possible directions. - This state variable may seem a bit strange, but it will help the snake understand its general body position.
- Again, this will be a pair like
There are now 648 possible states, a much more manageable number for storing data on and not repeating unnecessary learning on similar scenarios.
Rewards
In the intro, I stated that you choose what sort of positive or negative reward should be given when something happens in the environment. What sorts of things should we be considering in the snake game?
- Eating an apple (big positive)
- Dying (big negative)
- Moving toward apple (small positive)
- Moving away from apple (small negative)
You may, at first, think that it is unnecessary to reward the snake for moving toward the apple, but that is the thought of someone who has not watched their snake move about board for 10 minutes during game 100 at length one—never dying—but also never touching the apple. It will, of course, repeat this snail pace at length two and onward after it finally accidentally bumps into an apple, don’t worry.
So how does the snake store its history of rewards to learn from them?
Let’s review: the snake chooses to take action a while in state s. After the action is taken, the snake is given reward R. We will use a CSV to store data about rewards: each state will be given a row and within it, there will be a two columns for each action (2 columns for each action left, straight, and right). One of these columns will store the number of times the action a has been tried in this state; we will call this number k(a). There will also be the total number of rewards ever given for this action a up to the kth time; we will call this Q_k(a).
When the snake is evaluating the optimal action, it will look to its current state’s row. Then, it will see which of the three actions has resulted in the highest average reward (Q_k(a) / k(a)) and select this action.
After the snake has chosen an action a, the reward will be added to Q_a(a), and k(a) will increase by one. Over time, this will result in the snake choosing the best action for the state s.
Exploration and Exploitation
There is a tension between learning, which often involves failing, and a greedy algorithm. An algorithm that always acts greedy may miss the opportunity to learn about a technique that results in even better outcomes. You can think of this as it being stuck in a local minimum. Luckily, we have a few ways to deal with this problem:
-
Setting high (“optimistic”) initial values for actions at each state encourages the snake to explore options that it has not tried yet. If you expect the snake to have a max reward of 1 but set all initial stored rewards to 2, the snake will attempt action a in state s and find that a is “less rewarding” than other actions in state s. Of course, a might actually be more rewarding in the long run, but the snake will initially assume that the options it has not tried will result in a better outcome.
-
Another option is introducing ε, a parameter that introduces chance into our action selection process. There is a 1 - ε chance that the algorithm will choose the greedy action, and there is a ε chance that it will randomly choose an action.
For my agent, I implemented both of these techniques separately. Unfortunately, I did not have time to actually tune ε, so there was a clear better performance with ε = 0.
Learning
Here’s our snake during its first few games. It has yet to learn that walls are bad or to seek the most direct path to an apple. The movement is uncoordinated and without direction.

Now, it has about 100 games under its belt. It is much better about hitting walls but has gotten to the stage where it will hit its own tail completely out of the blue. The movement is more directed but often uses diagonal paths.
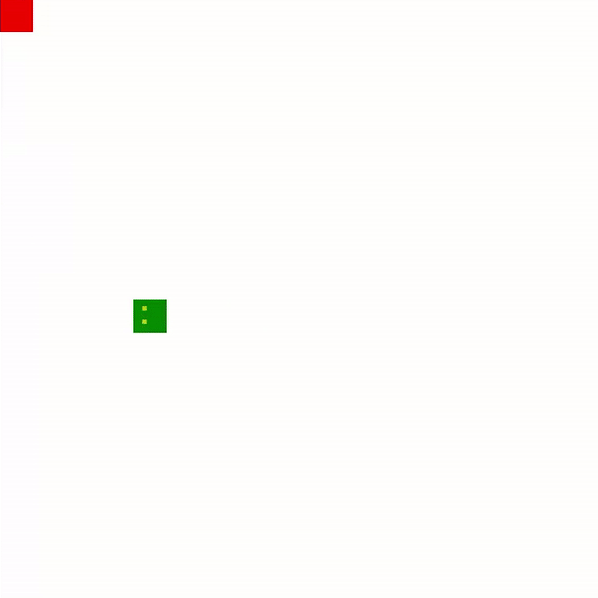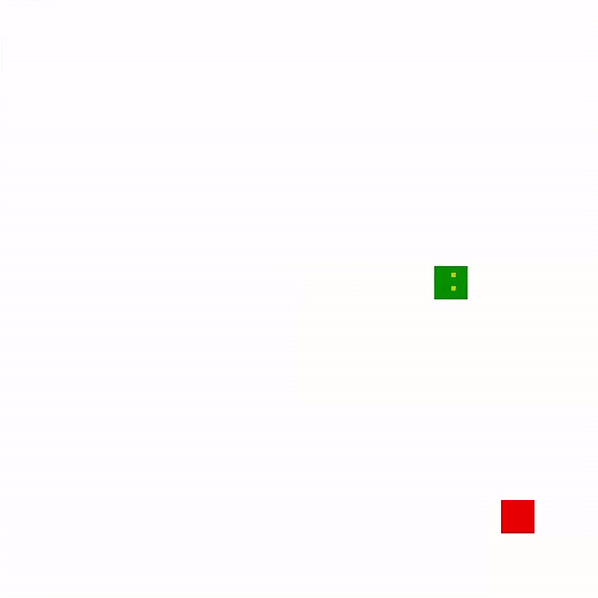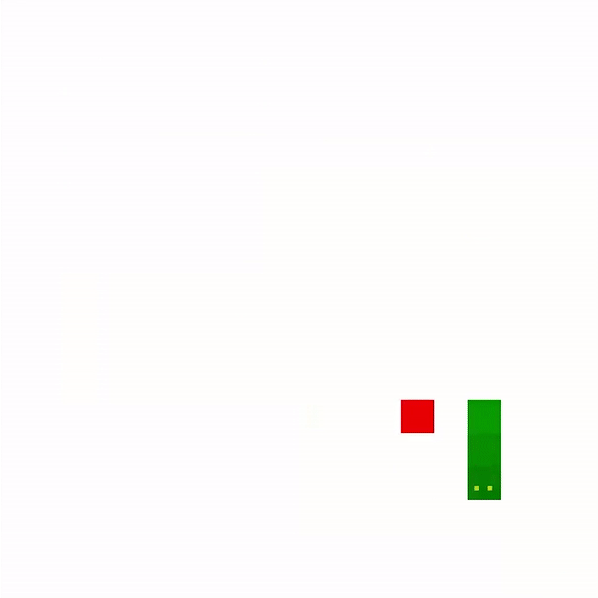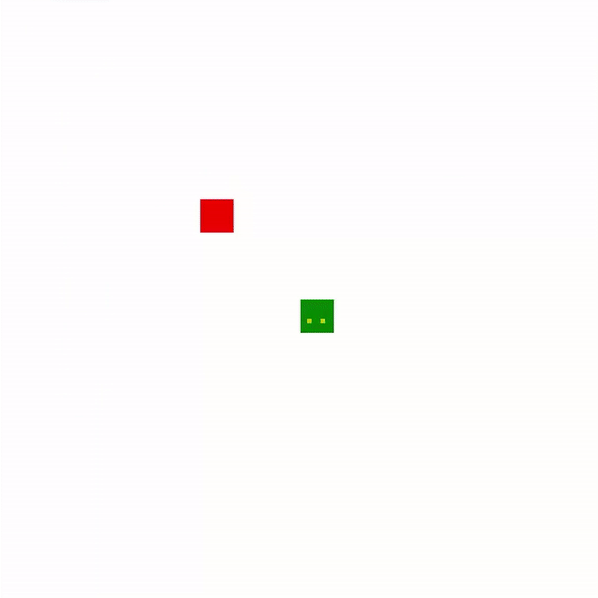
And, wow, look at 1,000 games! Its movements are much more similar to a human player, using switchbacks to its advantage as length increases. While it is ultimately defeated by its own tail, it takes a quite while for it to get trapped.
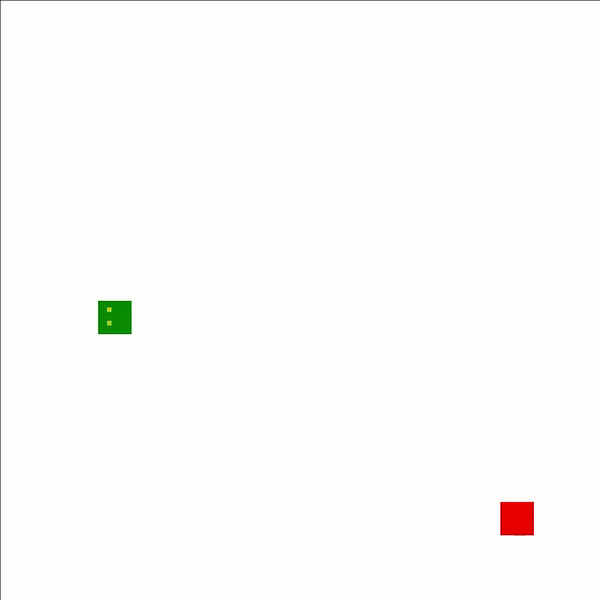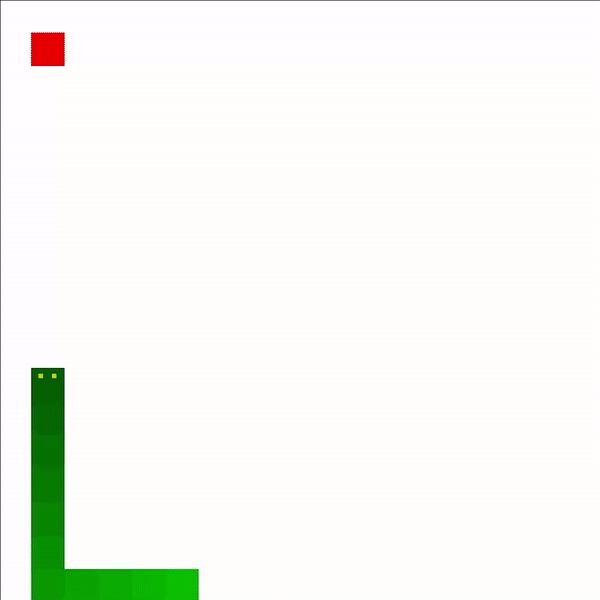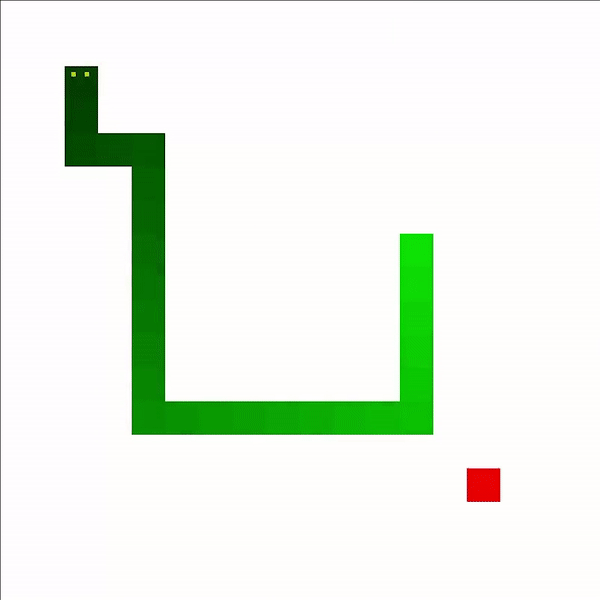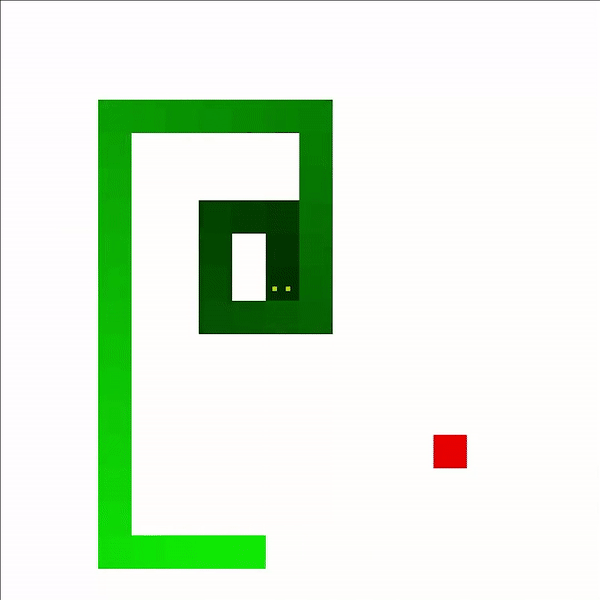
Citations
- A. G. Barto and R. S. Sutton, Reinforcement learning: An introduction (adaptive computation and machine learning), 2nd ed. MIT Press, 2014, 2015. [Online]. Available: https://web.stanford.edu/class/psych209/Readings/SuttonBartoIPRLBook2ndEd.pdf [Accessed: 15-Dec-2021].
- This book is very long and very useful. Be sure to start at the beginning if you haven’t done RL before because it adds pieces of information throughout.
-
C. Szepesvari, “Algorithms for reinforcement learning - university of Alberta,” Csaba Szepesvári, 09-Jun-2009. [Online]. Available: https://sites.ualberta.ca/~szepesva/papers/RLAlgsInMDPs.pdf. [Accessed: 15-Dec-2021].
-
D. Silver, “Lecture 1: Introduction to reinforcement learning,” David Silver. [Online]. Available: https://www.davidsilver.uk/wp-content/uploads/2020/03/intro_RL.pdf. [Accessed: 15-Dec-2021].
- H. de Harder, “Snake played by a deep reinforcement learning agent,” Medium, 09-Aug-2020. [Online]. Available: https://towardsdatascience.com/snake-played-by-a-deep-reinforcement-learning-agent-53f2c4331d36. [Accessed: 15-Dec-2021].
Directions
Using the arrow keys to control direction, navigate around the board to collect apples and avoid hitting the borders or your own tail. Eating an apple increases your length by one while hitting the borders or tail will cause the game to end. The goal is to get the longest length snake. The snake game is created using Python and the pygame library.

How to run
To play the snake game, you must have the pygame library. If you don’t have it, it can be installed using pip install pygame.
Download the repository from Github.
To run the game, navigate to the folder snake-game in terminal and run python snake_game.py. You can also run snake_game.py in any other ways you would run a python file.
Attribution
This version of the snake game was created by Alex and Lila. We used pygame to create this project.